Refactoring the Zeebe Node gRPC State Machine for Camunda Cloud: Part One
Building a state machine with business rules to deal with connection characteristics
Preparing for the launch of Camunda Cloud, I turned on continuous integration testing for the Zeebe Node.js client against a running instance of a Camunda Cloud Zeebe cluster.
I was immediately forced to deal with something I’d been conveniently ignoring:
Camunda Cloud gRPC connections always report failure initially, before eventually succeeding.
This is because the connection to Camunda Cloud is via a TLS-enabled Nginx reverse proxy with OAuth authentication. This causes the current gRPC client state machine to emit intermediate connection failure events before emitting an eventual “READY” state.
This “connection characteristic” differs from the behaviour of the non-proxied connection over a Docker network (the current CI test environment in CircleCI) or against a non-proxied broker on a remote machine (my personal production setups not using Camunda Cloud).
How that looks for a user:
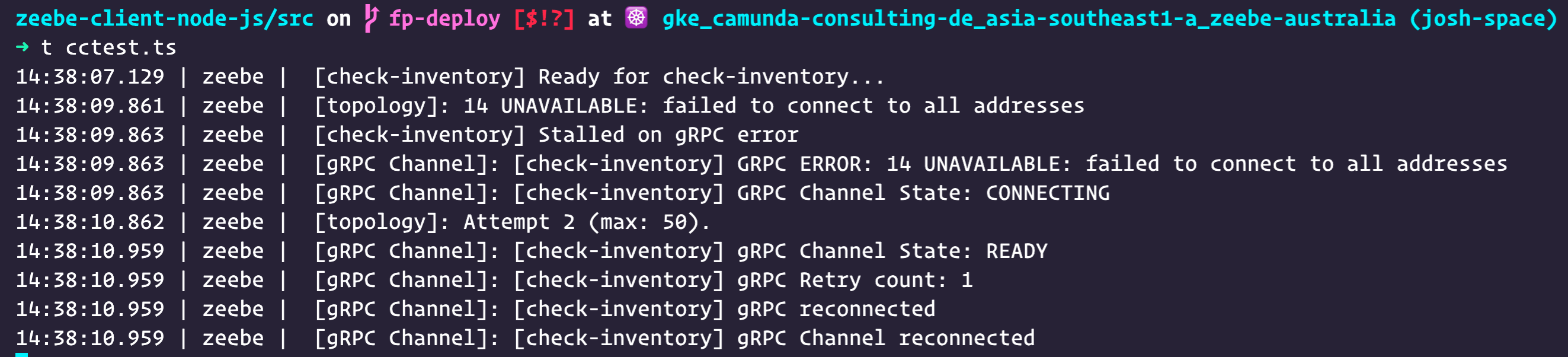
(This is using the new, in 0.23.0-alpha.1, default ZBSimpleLogger that outputs unstructured human-readable strings)
I had been ignoring this as “expected behaviour (for now)”, and my reticular activating system had conveniently made it invisible to me.
The failure of the integration tests made it abundantly clear that this is actually not expected behaviour in the formal specifications for the client (the tests).
Designing for Developer UX
This is bad Developer Experience (DX) design.
When developers are using Zeebe Node for the first time against Camunda Cloud, they don’t know what they are doing and they don’t know if they are doing it right.
When it is not working as they expect, they don’t know whether it is that their expectation is erroneous, or they have done something incorrectly. Users are often unaware even that they have a model of the system composed of expectations they hold as a hypothesis. Instead, they think: “Something is wrong. This is not working.”
There are four things that can be at the cause of this:
- The user has missed a step or made a mistake in their code or configuration.
- There is an intermittent failure condition (network down, service interruption).
- There is a bug in the library.
- The user’s expectation is incorrect (actual behaviour is correct, expected behaviour is incorrect).
Surfacing that last one - the unexamined hypotheses that the user holds about the system as their working model of the system - is why bug reports request “Expected Behaviour” and “Actual Behaviour” in their templates.
Any message presented to the user while they are developing their model of the system must take into account that the user’s model is unformed, and also that the user is usually not consciously forming the model.
I mean any message. A DEBUG level informational message in the Zeebe broker log has been a source of confusion for new users. They frequently interpret it as an error message (an example from the Zeebe Forum), and we are refactoring it to either reword it - taking into account the user’s uncertainty - or just take it out completely (GitHub issue “Reword Blocking request DEBUG Message”).
This particular message in the Zeebe Node client - that every single connection to Camunda Cloud always emits an error - is terrible for UX.
New users have enough uncertainty already. This behaviour guarantees that even if they do everything correctly, they are still going to be thinking: “I’ve done something wrong, it’s not working.”
And if they have done something incorrectly and it is really not working, this message provides them with no clue as to what that is, and will lead them on a wild-goose chase.
It has to go.
The Current gRPC State Machine
The current gRPC connection state machine has evolved over time. It started off pretty simple, then evolved to support client-side retry logic for network-related gRPC Error 14 but not business errors, emit connection-level error events, a ready event for the downstream Node-RED client, and managing the gRPC Error 8 event for Broker back pressure response.
As these features were added, the responsibility for managing the representation of the current connection state (that’s a true variable in the code), debouncing transitions (the channel state can flap about wildly during retries when it does go down - and this requires managing more state: time), and attaching various different retry and user-defined event handlers (if you add one for worker job streaming to the same connection used for client commands, it gets called for both), got split between the ZBClient, ZBWorker, and GRPCClient classes. This happened because these various patches were made one after the other, with no refactoring.
Now, adding the concept of “connection characteristics” will exponentially complicate already fragile code. State management is the bane of program correctness and a source of interminable bugs and edge conditions. State needs to be coalesced as an encapsulated concern in an application to avoid leaking this complexity into the other components in an application, and making changes to state management a distributed concern that touches many components.
See the article “Avoiding Global Mutable State in Browser JS” and the “Valid use of variables” section in the article “Shun the mutant - the case for const” for more discussion about this.
That implementing connection characteristics requires changes to multiple components is a code smell that indicates there is a first-class concern with no, or an incorrectly bounded, materialised entity in the code.
It is time for a significant refactor. The time required for this refactor is not trivial, and I conveniently ignored the error message until it became a failing test suite, then looked long and hard at the code before committing to this.
This is a significant part of the Zeebe Node client - managing the state of the gRPC connection and providing an ergonomic API to signal and handle various failure conditions. However, you don’t have to be Einstein to realise that:
“We can not solve our problems with the same level of thinking that created them.” - Albert Einstein
In this case, adding the concept of “Connection Characteristics” with differential behaviours to a non-first class abstraction is asking for a million bug reports and an unending game of whack-a-mole where fixing one problem causes problems with other behaviours.
No thanks. I’ll suck up the refactor costs.
The code should model the domain. We now have in the domain “various gRPC connection classes with different business rules for handling their characteristics”, so we are going to refactor the code to model that bounded context.
Fortunately, I already have the behavioural specification written - my integration tests. If I change nothing in those, I just have to make Camunda Cloud’s integration test go green and keep the CircleCI one green, and I can be confident that it works as expected.
As Evan Burchard explains, in his excellent book “Refactoring JavaScript: Turning Bad Code into Good Code":
When we have any code that lacks tests (or at least a documented way of executing it), we do not want to change this code. We can’t refactor it, because we won’t be able to verify that the behavior doesn’t change.
Step One: Explain it in plain language
The first step is to write a specification in a non-executable language - aka plain English.
This is the initial specification, and it should strive to be an unambiguous definition.
I created a GitHub issue “Manage that Camunda Cloud connections always error before eventually succeeding”, and described the motivation for the refactor in there.
Then, I added a design specification as a comment.
I am going to separate the functionality into two layers:
- The underlying GRPCClient that manages the gRPC connection and emits state events.
- An intermediary Business Rules component that models the connection characteristics and ensures that various connections behave the same at the API level.
There is one concern whose location I am not yet clear about. I am thinking that the GRPCClient will have a method to turn on a buffering mode, where it buffers state transition events, and then returns the eventual state with a list of intermediate transitions, after a specified period of time.
This allows me to turn this on for Camunda Cloud connections, and throw away those initial failures, reporting only the ultimate result.
This may complicate the GRPCClient state machine by adding an additional state machine to it (managing time, and the current operational mode), so I may move this into the Connection Characteristics component. We shall see. It’s a working hypothesis. Gotta start with some kind of vision, and keep re-evaluating along the way.
OK, let the fun begin!
About me: I’m a Developer Advocate at Camunda, working primarily on the Zeebe Workflow engine for Microservices Orchestration, and the maintainer of the Zeebe Node.js client. In my spare time, I build Magikcraft, a platform for programming with JavaScript in Minecraft.


